Obtenga beneficios adicionales
Aún no tiene una suscripción a Virtual Pro?
Para acceder a este contenido se requiere una suscripción
Obtenga beneficios adicionales
Aún no tiene una suscripción a Virtual Pro?
Para acceder a este contenido se requiere una suscripción
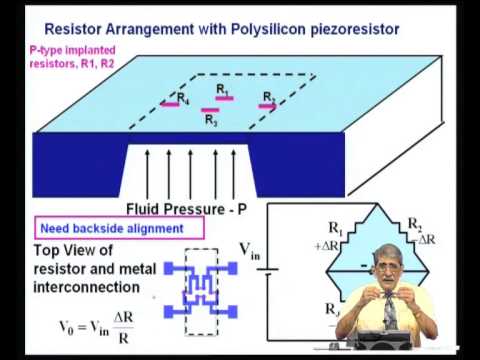
Para muchas aplicaciones, encontrar casos raros o valores atípicos puede ser más interesante que encontrar patrones comunes. Los trabajos existentes sobre la detección de valores atípicos nunca tienen en cuenta el contexto de la web profunda. En este trabajo, argumentamos que, para muchos escenarios, es más significativo detectar valores atípicos en la web profunda. En el contexto de la web profunda, los usuarios deben enviar consultas a través de una interfaz de consulta para recuperar los datos correspondientes. Por tanto, los métodos tradicionales de minería de datos no pueden aplicarse directamente. La principal contribución de este artículo es el desarrollo de un nuevo método de minería de datos para la detección de valores atípicos en la web profunda. En nuestro enfoque, el espacio de consulta de una fuente de datos de la web profunda se estratifica en base a una muestra piloto. El muestreo de vecindad y el muestreo de incertidumbre se desarrollan en este trabajo con el objetivo de mejorar el recuerdo y la precisión basados en la estratificación. Por último, una cuidadosa evaluación del rendimiento de nuestro algoritmo confirma que nuestro enfoque puede detectar eficazmente los valores atípicos en la web profunda.
Esta es una versión de prueba de citación de documentos de la Biblioteca Virtual Pro. Puede contener errores. Lo invitamos a consultar los manuales de citación de las respectivas fuentes.
Artículo:
Predicción tridimensional de la fuerza de un sensor táctil flexible basado en redes neuronales de función de base radial
Artículo:
Desarrollo de un sensor de caucho conductor sensible a la presión para analizar la lesión meniscal en modelos porcinos
Artículo:
Caracterización de las nanomicelas de autoensamblaje de caseína/queratina
Artículo:
Análisis de nanotubos SC5C7p,q y NPHXp,q mediante índices topológicos
Libro:
Nanotecnología, salud y bioética (entre la esperanza y el riesgo)
Artículo:
Creación de empresas y estrategia : reflexiones desde el enfoque de recursos
Artículo:
Importancia, manejo y control de extraíbles e incrustaciones (pitch) en la fabricación de papel
Libro:
Tratamientos avanzados de aguas residuales industriales
Libro:
Planta de tratamiento de aguas residuales

Virtual Pro es un portal virtual de formación, investigación y comunicación especializado en procesos industriales.

� 2021, Virtual Pro �, una marca de Grupo INGCO. Todos los derechos reservados